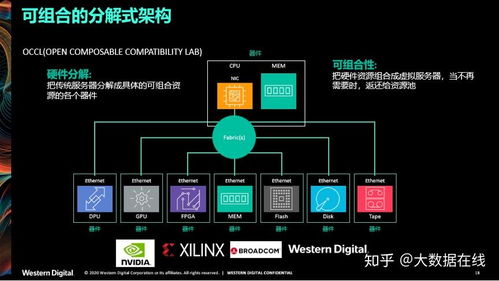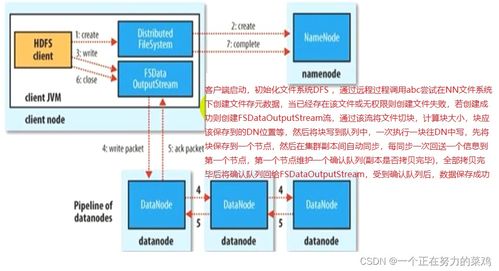
HDFS(Hadoop分布式文件系統)作為大數據生態系統的核心組件,為海量數據提供了可靠的存儲基礎,并高效支撐起數據處理流程。它通過分布式架構,將數據分散存儲在多臺機器上,實現高吞吐量的數據訪問和強大的容錯能力。
在數據存儲方面,HDFS采用主從架構,包括NameNode和DataNode。NameNode負責管理文件系統的元數據,而DataNode則存儲實際的數據塊。這種設計不僅支持PB級數據的存儲,還通過數據副本機制確保數據的安全性,即使部分節點發生故障,系統仍能正常運行。
對于數據處理,HDFS與MapReduce、Spark等計算框架緊密集成。數據可以本地化處理,減少網絡傳輸開銷,提升處理效率。HDFS支持流式數據訪問,適合批處理和分析任務,廣泛應用于日志存儲、數據倉庫和機器學習等場景。
HDFS不僅是一個高效的數據存儲解決方案,更是數據處理生態中不可或缺的支撐服務,為企業和研究機構提供了穩定、可擴展的大數據基礎。